
Resetting vSphere 6.x ESXi Account Lockouts via SSH
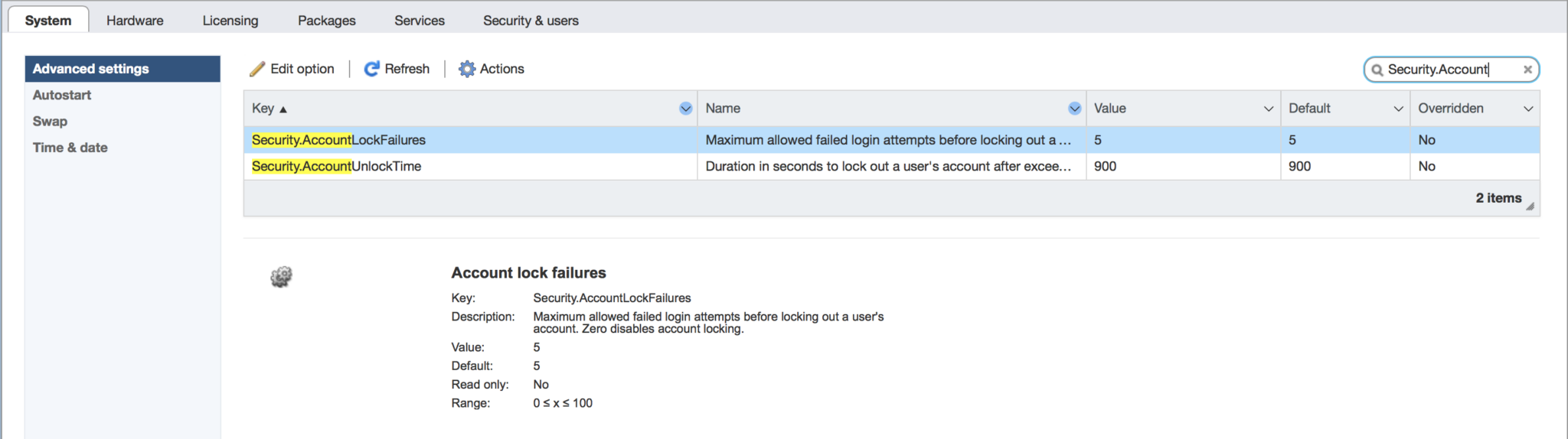
VMware vSphere has had a good security feature added since vSphere ESXi 6.0 to add a root account lockout for safety. After a number of failed login attempts, the server will trigger a lockout. This is a good safety measure for when you have public facing servers and is even important for internally exposed servers … Read more


