
Cisco Workload Optimization Manager 2.2 Released!
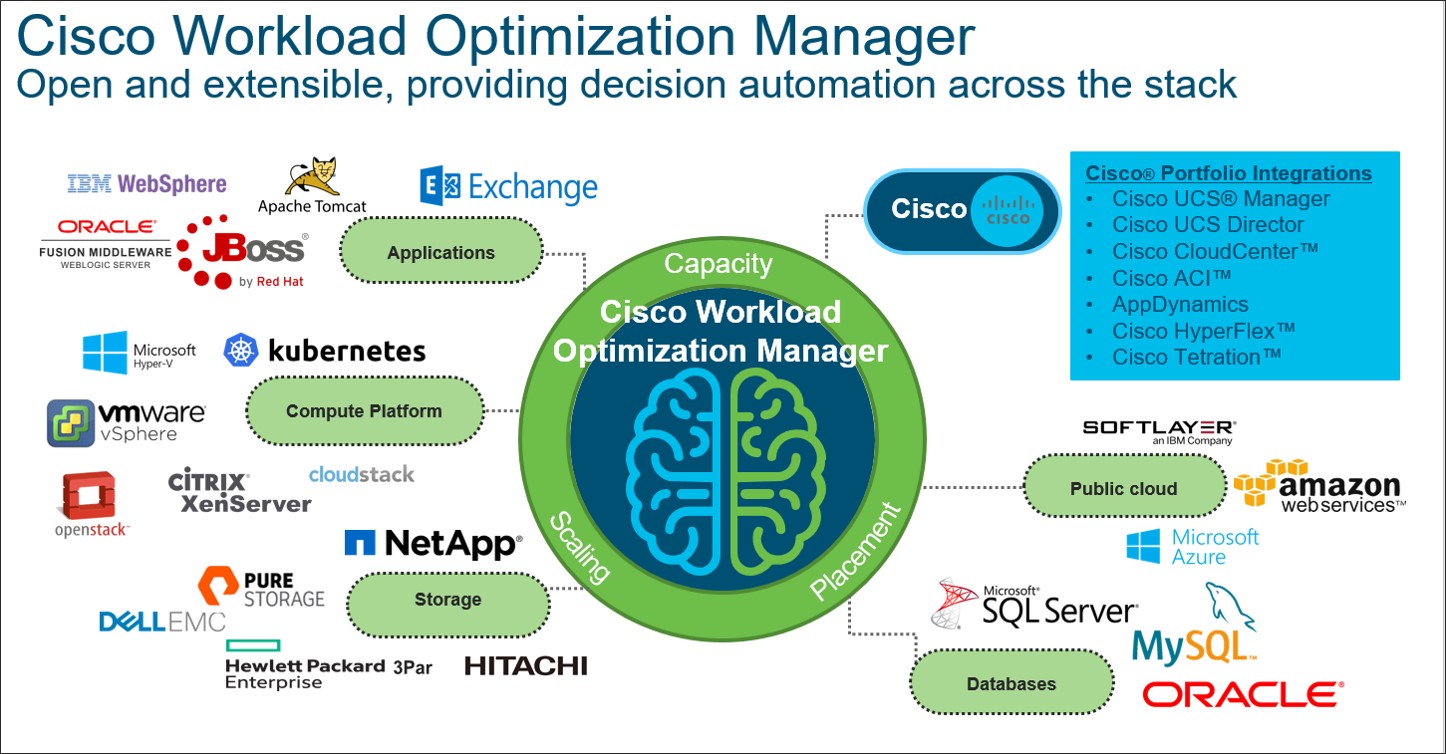
The Turbonomic and Cisco teams have released our next Cisco Workload Optimization Manager platform with the most recent update to version 2.2, packed with much more cloudy goodness and also with the addition of new targets and more features in the cloud for both planning and real-time optimization. One of my favorite parts of building … Read more


